BOLD, non-BOLD, and TE-dependence with tedana#
Important
This chapter should differentiate itself from Signal_Decay by focusing on the application of (2) to decompositions, rather than raw signal compared between active and inactive states.
We may want to describe adaptive masking, data whitening, the model fit metrics, and post-processing methods (e.g., MIR) in this page as well.
Important
The general flow of this chapter should be:
Explain the monoexponential decay equation, but primarily reference back to Signal_Decay.
Walk through optimal combination and adaptive masking somewhere around here.
Describe why multi-echo denoising can’t be done directly to the raw signal and why ICA is necessary.
This mean talking about noise, really, and why the FIT method (volume-wise T2*/S0 estimation) is generally considered too noisy for practical application.
Walk through TEDPCA as well.
The TE-(in)dependence models.
Apply the models to a simulated component, as well as multiple real components.
Show model fit for different components.
Compare optimally combined, denoised, and high-kappa data.
Describe post-processing methods, like minimum image regression and tedana’s version of global signal regression.
This notebook uses simulated T2*/S0 manipulations to show how TE-dependence is leveraged to denoise multi-echo data.
The equation for how signal is dependent on changes in S0 and T2*:
Plot simulations of BOLD and non-BOLD signals as a function of echo time#
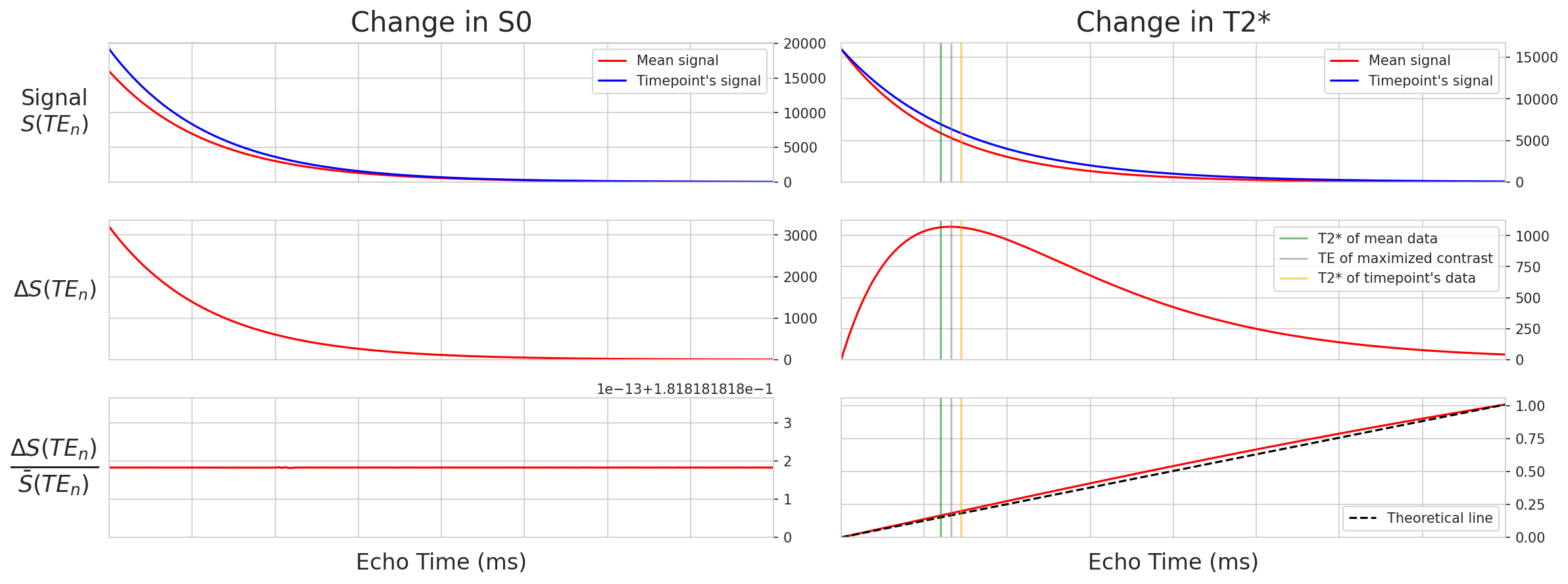
Fig. 16 Simulations of BOLD and non-BOLD signals as a function of echo time#
Make design matrices#
For TEDPCA and TEDICA, we use regression to get parameter estimates (PEs; not beta values) for component time-series against echo-specific data, and substitute those PEs for \({\bar{S}(TE_k)}\). At some point, I would like to dig into why those parameter estimates are equivalent to \({\bar{S}(TE_k)}\) for our purposes.
TE-independence model#
\(\frac{{\Delta}S_0}{S_0}\) is a scalar (i.e., doesn’t change with TE), so we ignore that, which means we only use \({\bar{S}(TE_k)}\) (mean echo-wise signal).
Thus,
and for TEDPCA/TEDICA,
Lastly, we fit X to the data and evaluate model fit.
TE-dependence model#
\(-{\Delta}{R_2^*}\) is a scalar, so we ignore it, which means we only use \({\bar{S}(TE_k)}\) (mean echo-wise-signal) and \(TE_k\) (echo time in milliseconds).
Thus,
and for TEDPCA/TEDICA,
Lastly, we fit X to the data and evaluate model fit.
Fitted curves for S0-perturbed signal#
The predicted curve for the S0 model matches the real curve perfectly!
Rho: 7.406633617276125e+18
Kappa: 187.14447414118752
Real delta S0: 3200.0
Delta S0 from results: 3200.00000019387
Fitted curves for R2*-perturbed signal#
For some reason, the predicted curve for the R2 model doesn’t match the real signal curve. What’s with this mismatch?
It seems like the mismatch increases as the difference between the fluctuating volume’s R2 and the mean R2 increase. The fitted curve seems to actually match the mean signal, not the perturbed signal!
Rho: 156.88794057276826
Kappa: 31513.965175231362

Fig. 17 Fitted curves for R2*-perturbed signal#
Now let’s apply this approach to components#
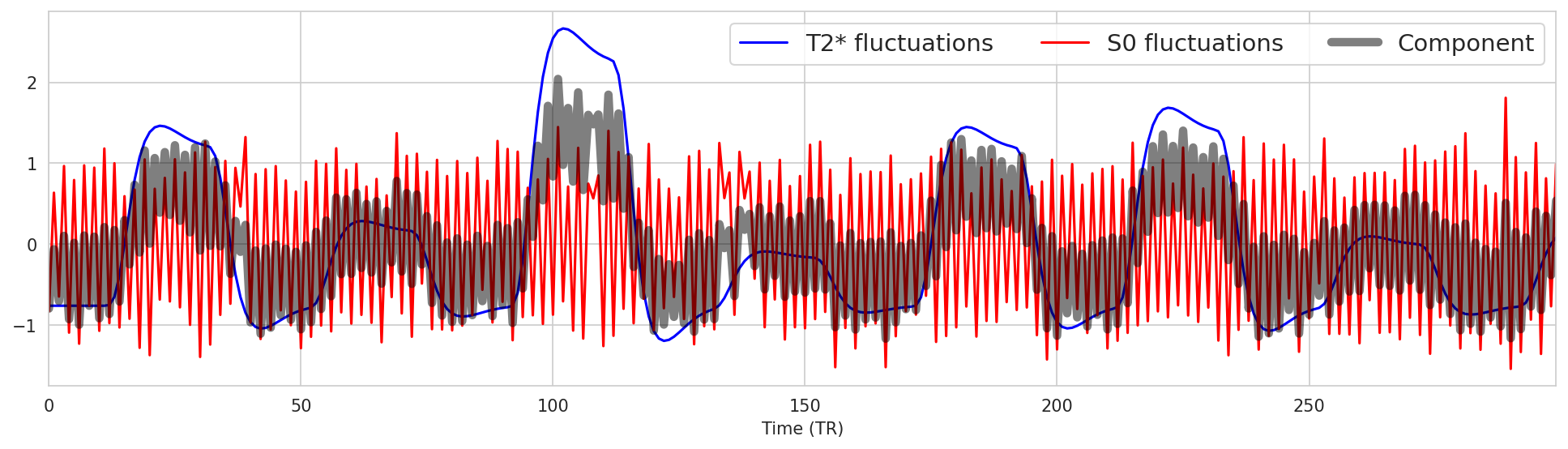
Fig. 18 Now let’s apply this approach to components#
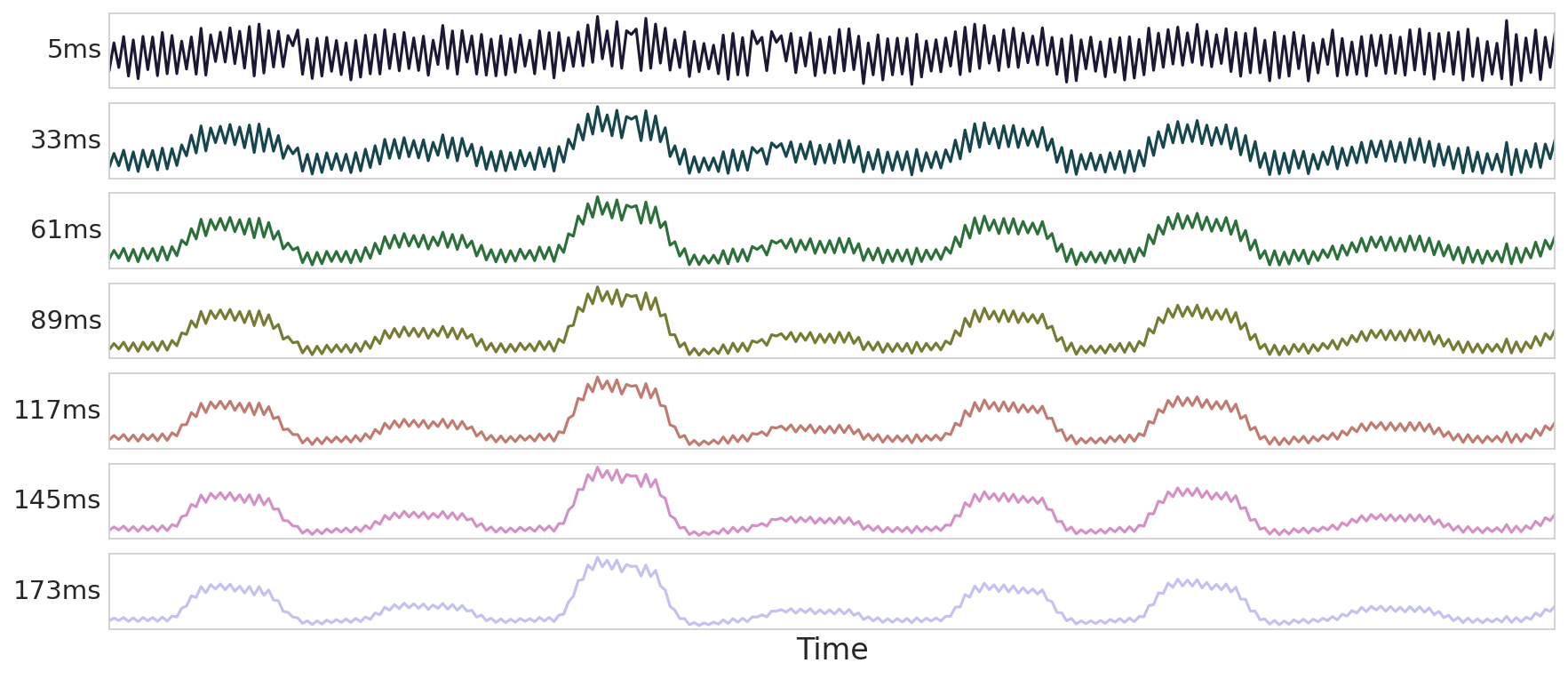
Fig. 19 Now let’s apply this approach to components again.#
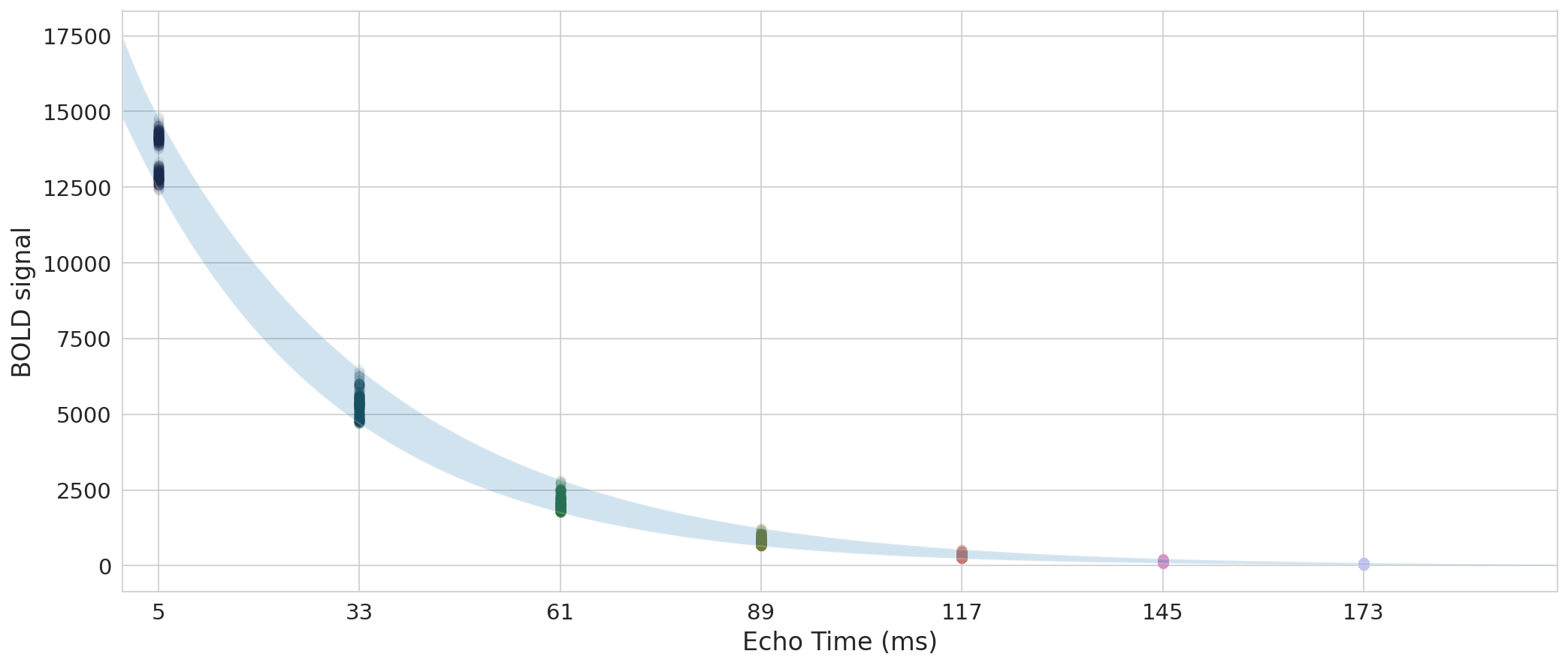
Fig. 20 Now let’s apply this approach to components again.#
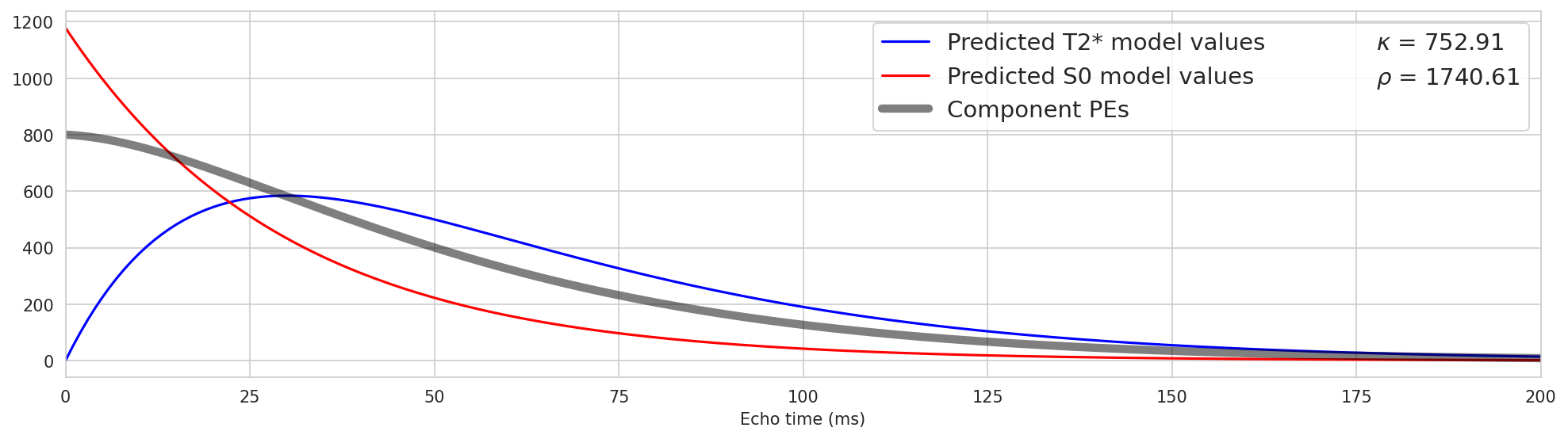
Fig. 21 Now let’s apply this approach to components again.#
Algorithm 1 (Minimum image regression)
Inputs
\(\mathbf{O}\) is the matrix of optimally combined (OC) data, of shape \(v \times t\), where \(v\) is the number of voxels in the brain mask and \(t\) is the number of timepoints in the scan.
\(\mathbf{M}\) is the mixing matrix from the ICA decomposition, of shape \(c \times t\), where \(c\) is the number of components.
\(W\) is the set of indices of all components in \(\mathbf{M}\): \(W = \{1, 2, 3, ..., c\}\)
\(N\) is the set of indices of all non-ignored components (i.e., all accepted or BOLD-like, and rejected or non-BOLD components) in \(\mathbf{M}\): \(N \in \mathbb{N}^k \text{ s.t } 1 \leq k \leq c, N \subseteq W\)
\(A\) is the set of indices of all accepted (i.e., BOLD-like) components in \(\mathbf{M}\): \(A \in \mathbb{N}^l \text{ s.t } 1 \leq l \leq k, A \subseteq N\)
Outputs
Multi-echo denoised data without the T1-like effect, referred to as \(\mathbf{D}\) or MEDN+MIR.
Multi-echo BOLD-like data without the T1-like effect, referred to as \(\mathbf{H}\) or MEHK+MIR.
ICA mixing matrix with the T1-like effect removed from component time series (\(\mathbf{K}\)).
Map of the T1-like effect (\(\mathbf{m}\))
Algorithm
The voxel-wise means (\(\mathbf{\overline{O}} \in \mathbb{R}^{v}\)) and standard deviations (\(\mathbf{\sigma_{O}} \in \mathbb{R}^{v}\)) of the optimally combined data are computed over time.
The optimally combined data are z-normalized over time (\(\mathbf{O_z} \in \mathbb{R}^{v \times t}\)).
The normalized optimally combined data matrix (\(\mathbf{O_z}\)) is regressed on the ICA mixing matrix (\(\mathbf{M} \in \mathbb{R}^{c \times t}\)) to construct component-wise parameter estimate maps (\(\mathbf{B} \in \mathbb{R}^{v \times c}\)).
\[ \mathbf{O_{z}} = \mathbf{B} \mathbf{M} + \mathbf{\epsilon}, \enspace \mathbf{\epsilon} \in \mathbb{R}^{v \times t} \]\(N\) is used to select rows from the mixing matrix \(\mathbf{M}\) and columns from the parameter estimate matrix \(\mathbf{B}\) that correspond to non-ignored (i.e., accepted and rejected) components, forming reduced matrices \(\mathbf{M}_N\) and \(\mathbf{B}_N\). The normalized time series matrix for the combined ignored components and variance left unexplained by the ICA decomposition is then computed by subtracting the scalar product of the non-ignored beta weight and mixing matrices from the normalized OC data time series (\(\mathbf{O_{z}}\)). The result is referred to as the normalized residuals time series matrix (\(\mathbf{R} \in \mathbb{R}^{v \times t}\)).
\[ \mathbf{R} = \mathbf{O_{z}} - \mathbf{B}_N \mathbf{M}_N, \enspace \mathbf{B}_N \in \mathbb{R}^{v \times |N|}, \enspace \mathbf{M}_N \in \mathbb{R}^{|N| \times t} \]We can likewise construct the normalized time series of BOLD-like components (\(\mathbf{P} \in \mathbb{R}^{v \times t}\)) by multiplying similarly reduced parameter estimate and mixing matrices composed of only the columns and rows, respectively, that are associated with the accepted components indexed in \(A\). The resulting time series matrix is similar to the time series matrix referred to elsewhere in the manuscript as multi-echo high-Kappa (MEHK), with the exception that the component time series have been normalized prior to reconstruction.
\[ \mathbf{P} = \mathbf{B}_A \mathbf{M}_A, \enspace \mathbf{B}_A \in \mathbb{R}^{v \times |A|}, \enspace \mathbf{M}_A \in \mathbb{R}^{|A| \times t} \]The map of the T1-like effect (\(\mathbf{m} \in \mathbb{R}^{v}\)) is constructed by taking the minimum across timepoints from the normalized MEHK time series (\(\mathbf{P}\)) and then mean-centering across brain voxels. Let \(J = \{1, ..., t\}\) denote the indices of the columns of matrix \(\mathbf{P}\), and let \(p_{ij}\) denote the value of the element \(\mathbf{P}[i,j]\).
\[ \mathbf{q_{i}} = \min_{j\in{J}}p_{ij} \quad \forall i = 1,...,v \]\[ \mathbf{m} = \mathbf{q} - \mathbf{\overline{q}}, \enspace \mathbf{q} \in \mathbb{R}^{v} \]The standardized optimally combined time series matrix (\(\mathbf{O_z}\)) is regressed on the T1-like effect map (\(\mathbf{m}\)) to estimate the volume-wise global signal time series (\(\mathbf{g} \in \mathbb{R}^t\)).
\[ \mathbf{O_{z}} = \mathbf{m} \otimes \mathbf{g} + \mathbf{\epsilon}, \enspace \mathbf{\epsilon} \in \mathbb{R}^{v \times t} \]Where \(\otimes\) is the outer product.
The normalized BOLD time series matrix (\(\mathbf{P}\)) is then regressed on this global signal time series (\(\mathbf{g}\)) in order to estimate a global signal map (\(\mathbf{s} \in \mathbb{R}^v\)) and the normalized BOLD time series matrix without the T1-like effect (\(\mathbf{E} \in \mathbb{R}^{v \times t}\)).
\[ \mathbf{P} = \mathbf{g} \otimes \mathbf{s} + \mathbf{E} \]The time series matrix of BOLD-like components without the T1-like effect (MEHK+MIR, \(\mathbf{H} \in \mathbb{R}^{v \times t}\)), scaled to match the original OC time series matrix, is constructed by multiplying each column of \(\mathbf{E}\) by the vector \(\mathbf{\sigma_{O}}\).
\[\begin{split} \mathbf{H} = \mathbf{E} \circ \underbrace{ \pmatrix{ \mathbf{{\sigma_{O}}_1} & \cdots & \mathbf{{\sigma_{O}}_1}\\ \vdots & \vdots & \vdots \\ \mathbf{{\sigma_{O}}_v} & \cdots & \mathbf{{\sigma_{O}}_v}\\ } }_{t} \end{split}\]Where \(\circ\) is the Hadamard product for element-wise multiplication of two matrices.
The ICA-denoised time series without the T1-like effect (MEDN+MIR, \(\mathbf{D} \in \mathbb{R}^{v \times t}\)) is constructed by adding the residuals time series (\(\mathbf{R}\)) to the normalized BOLD time series (\(\mathbf{E}\)), multiplying each column of the result by the vector \(\sigma_{O}\), and adding back in the voxel-wise mean of the OC time series (\(\mathbf{\overline{O}}\)).
\[\begin{split} \mathbf{D} = \mathbf{\overline{O}} + (\mathbf{E} + \mathbf{R}) \circ \underbrace{ \pmatrix{ \mathbf{{\sigma_{O}}_1} & \cdots & \mathbf{{\sigma_{O}}_1}\\ \vdots & \vdots & \vdots \\ \mathbf{{\sigma_{O}}_v} & \cdots & \mathbf{{\sigma_{O}}_v}\\ } }_{t} \end{split}\]The T1c-corrected ICA mixing matrix is then derived by regressing the global signal time series \(\mathbf{g}\) from each component’s time series. Let \(\mathbf{Q}\) be the associated parameter estimate matrix (\(\mathbf{Q} \in \mathbb{R}^{c \times t}\)).
\[ \mathbf{M} = \mathbf{Q}\mathbf{g} + \mathbf{K} \]\[ \mathbf{K} = \mathbf{M} - \mathbf{Q}\mathbf{g} \]