Acquiring Multi-Echo Data#
How to approach setting multi-echo acquisition parameters#
There is no definitively optimal parameter set for multi-echo fMRI acquisition or any fMRI acqusition. The guidelines for optimizing parameters are similar to single-echo fMRI. An overall recommendation is to choose single-echo sequence parameters that meet the priorities of a study with regards to spatial resolution, spatial coverage, sample rate, signal-to-noise ratio, signal drop-out, distortion, and artifacts. Then make the least significant parameter changes needed to acquire multi-echo fMRI data. “Least significant” is study-specific. In one study, one might have a 1.5 sec TR with single echo and multi-echo echo is possible with a 1.75 sec TR without impacting study goals. In another study, slices might cover cortex and cerebellum with the largest plausible participant brains, but 10% less coverage would include full brain coverage for most participants and all key study-specific regions-of-interest.
A minimum of 3 echoes is required for methods like tedana that fit echoes to a decay curve. There is typically at least one echo that is earlier and one that is later than the TE one would use for single-echo \(T_2^*\) weighted fMRI. It is also important to make sure at least 3 echoes retain a useful amount of signal. On a 3T MRI, a few regions, particularly areas like orbitofrontal cortex, won’t have sufficient signal for \(TE\geq45ms\), and there will be more noticable signal loss with \(TE\geq50ms\). There are multi-echo fMRI studies that successfully use longer 3rd echo times, but being aware of this signal loss is important, and one might benefit from keeping echo times shorter if one is prioritizing acquisitions in typically high signal dropout regions.
More than 3 echoes may be useful, because that would allow for more accurate estimates of BOLD and non-BOLD weighted fluctuations, but more echoes have an additional time cost, which would result in either less spatiotemporal coverage or more acceleration. Whether the benefits of more echoes balance out the additional costs is an open research question.
Additional recommendations and guidelines for acquiring multi-echo fMRI data are discussed in the appendix of Dipasquale et al. (2017)
It is also useful to look at existing publications.
Here is an always outdated list of multi-echo fMRI publications
Here is an often outdated list of multi-echo fMRI open datasets that may be useful to visualize and measure data quality in datasets with similar scientific goals.
Here is a spreadsheet that shows possible acquisition parameters on a specfic 3T scanner. This is useful to get a sense of what is possible when evaluating parameter options. That is, one can see how much a TR will increase for 3, 4, and 5 echoes for a given set of parameters and how different parameter changes, such as more acceleration, will alter the echo times and the TR. Note that this spreadsheet maps a wide range of parameter options and that go beyond advisable options. Just because it is possible to collect data with in-slice acceleration of 3 and multi-slice acceleration of 4 (a \(\sqrt{12}\) drop in signal-to-noise ratio & more artifacts) doesn’t mean it’s advisable.
Collecting and examining pilot scans is always recommended. Look at some data collected for your specific study. Look at signal quality, artifacts, dropout, and if potential effects of interest are sufficiently statistically robust.
Note
There are other methods and use multi-echo acqusitions.
For example a **dual echo** method which uses a very early (~5ms)
first echo in order to clean data. For more information on this method, see [Bright and Murphy (2013)](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3518782/)
Available multi-echo fMRI sequences#
We have attempted to compile some basic multi-echo fMRI protocols in an OSF project. The parameter choices in these protocols run and seem reasonable, but they have not been optimized for a specific situation. They are a good starting point for someone designing a study, but should not be considered canonical. If you would like to use one of them, please customize it for your own purposes and make sure to run pilot scans to test your choices.
Siemens#
For Siemens users, there are two options for Works In Progress (WIPs) Sequences.
The Center for Magnetic Resonance Research at the University of Minnesota provides a custom MR sequence that allows users to collect multiple echoes (termed Contrasts). The sequence and documentation can be found here. For details on obtaining a license follow this link. By default the number of contrasts is 1, yielding a single-echo sequence. In order to collect multiple echoes, increase number of Contrasts on the Sequence Tab, Part 1 on the MR console.
The Martinos Center at Harvard also has a MR sequence available, with the details available here. The number of echoes can be specified on the Sequence, Special tab in this sequence.
GE#
GE users can request access to the HyperMEPI ATSM sequence. Request can be made through GE’s WeConnect Portal. This sequence has both hyperband, (GE’s term for simultaneous-multislice or multiband) and multi-echo. Depending on scanner and software version, GE scanners have a limit on the total number of slices that can be collected during a single acquisition. This has the potential to limit the maximum duration of a multi-echo fMRI run.
Philips#
For Philips users, sequences can be defined using product software.
Multi-echo EPI (ME-EPI) can be acquired using the product software and can be combined with SENSE parallel imaging and MultiBand. The combination with MultiBand requires a SW release >R5.1 and MultiBand functionality to be present. No default ME-EPI are provided, but existing single-echo EPI sequences from the BOLD fMRI folder can be modified into multi-echo sequences by increasing the number of echoes. As a starting point to develop a 3 echo EPI protocol start by opening the default fMRI protocol and modify the following: increase number of echoes to 3 on the Contrast tab, set SENSE = 3, MB-SENSE = 3, set to 3mm isotropic voxels and adjust TEs to your preference.
Other available multi-echo MRI sequences#
In addition to ME-fMRI, other MR sequences benefit from acquiring multiple echoes, including T1-weighted imaging (MEMPRAGE) and susceptibility weighted imaging. While most of these kinds of sequences fall outside the purview of this documentation, quantitative T2* mapping is relevant since a baseline T2* map is used in several processing steps including optimal combination. While the T2* map estimated directly from fMRI time series is noisy, no current study quantifies the benefit to optimal combination or tedana denoising if a higher quality T2* map is used. Some benefit is likely, so, if a T2* map is independently calculated, it can be used as an input to many functions in the tedana workflow.
Warning
While tedana allows the input of a T2* map from any source, and a more accurate T2* map should lead to better results, this hasn’t been systematically evaluated yet.
There are many ways to calculate T2* maps, with some using multi-echo acquisitions. We are not presenting an expansive review of this literature here, but Cohen-Adad et al. [2012] and Ruuth et al. [2019] are good places to start learning more about this topic.
Acquisition parameter recommendations#
There is no empirically tested best parameter set for multi-echo fMRI acquisition. The guidelines for optimizing parameters are similar to single-echo fMRI. For multi-echo fMRI, the same factors that may guide priorities for single echo fMRI sequences are also relevant. Choose sequence parameters that meet the priorities of a study with regards to spatial resolution, spatial coverage, sample rate, signal-to-noise ratio, signal drop-out, distortion, and artifacts.
A minimum of 3 echoes is required for running the current implementation fo TE-dependent denoising in
tedana.
It may be useful to have at least one echo that is earlier and one echo that is later than the
TE one would use for single-echo T2* weighted fMRI.
More than 3 echoes may be useful, because that would allow for more accurate estimates of BOLD and non-BOLD weighted fluctuations, but more echoes have an additional time cost, which would result in either less spatiotemporal coverage or more acceleration. Where the benefits of more echoes balance out the additional costs is an open research question.
We are not recommending specific parameter options at this time. There are multiple ways to balance the slight time cost from the added echoes that have resulted in research publications. We suggest new multi-echo fMRI users examine the spreadsheet of publications that use multi-echo fMRI to identify studies with similar acquisition priorities, and use the parameters from those studies as a starting point. More complete recommendations and guidelines are discussed in the appendix of Dipasquale et al. [2017].
Note
In order to increase the number of contrasts (“echoes”) you may need to first increase the TR, shorten the first TE and/or enable in-plane acceleration. For typically used parameters see the ME-fMRI parameters section below.
Additional considerations#
Complex reconstruction#
It is possible to retain phase data when reconstructing multi-echo fMRI data. The phase data may be leveraged for a number of useful denoising and processing methods, including NORDIC [Vizioli et al., 2021, Dowdle et al., 2021, Dowdle et al., 2023], MEDIC dynamic distortion correction [Van et al., 2023], and improved T2* estimation [Cohen-Adad et al., 2012].
It’s important to remember that retaining phase data for each echo will effectively double the amount of data you end up with. This can also cause problems with online reconstruction, for example with Siemens machines running XA30.
No-excitation-pulse noise volumes#
In order to best use NORDIC, researchers should acquire no-RF noise volumes at the end of their fMRI runs.
ME-fMRI parameters#
The following section highlights a selection of parameters collected from published papers that have used multi-echo fMRI. You can see the spreadsheet of publications at spreadsheet of publications.
The following plots reflect the average values for studies conducted at 3 Tesla.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
metable = pd.read_csv(
"https://docs.google.com/spreadsheets/d/1WERojJyxFoqcg_tndUm5Kj0H1UfUc9Ban0jFGGfPaBk/export?gid=0&format=csv",
header=0,
)
# Coerce TE columns to numeric; determine number of echoes per study.
te_cols = ["TE1", "TE2", "TE3", "TE4", "TE5"]
for col in te_cols:
metable[col] = pd.to_numeric(metable[col], errors="coerce")
metable["n_echoes"] = metable[te_cols].notna().sum(axis=1)
# Plot echo-time distributions for studies with 3, 4, or 5 echoes.
n_echo_groups = [3, 4, 5]
palette = ["#4C72B0", "#DD8452", "#55A868"]
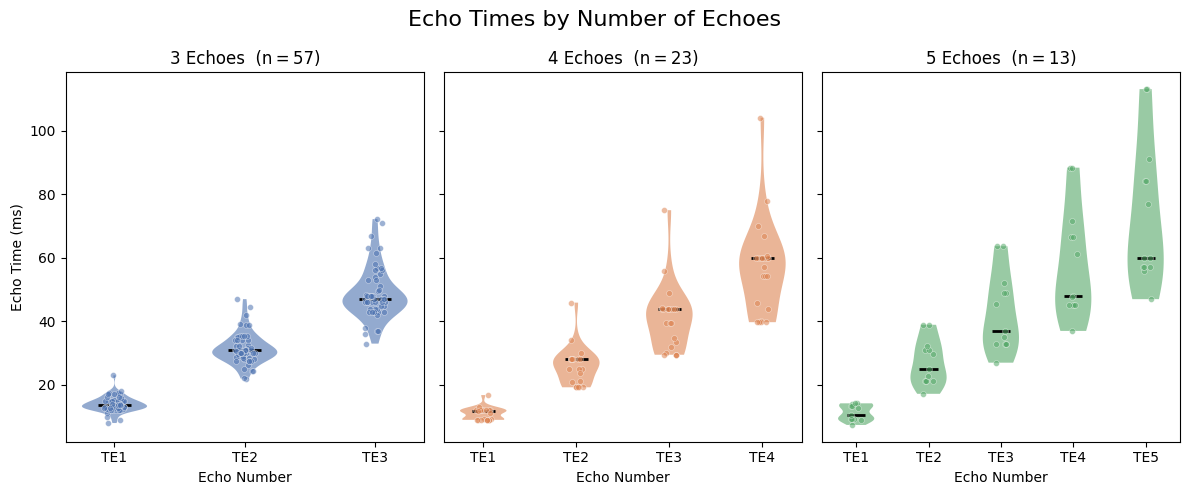
fig, axes = plt.subplots(1, 3, figsize=(12, 5), sharey=True)
fig.suptitle("Echo Times by Number of Echoes", fontsize=16)
rng = np.random.default_rng(42)
for ax, n_echoes, color in zip(axes, n_echo_groups, palette):
subset = metable[metable["n_echoes"] == n_echoes]
echo_data = [subset[f"TE{i + 1}"].dropna().values for i in range(n_echoes)]
positions = np.arange(1, n_echoes + 1)
# Violin bodies
parts = ax.violinplot(
echo_data, positions=positions, showmedians=True, showextrema=False
)
for pc in parts["bodies"]:
pc.set_facecolor(color)
pc.set_alpha(0.6)
parts["cmedians"].set_color("black")
parts["cmedians"].set_linewidth(2)
# Individual data points (jittered)
for pos, data in zip(positions, echo_data):
jitter = rng.uniform(-0.08, 0.08, size=len(data))
ax.scatter(
pos + jitter, data, s=18, color=color, alpha=0.55,
linewidths=0.4, edgecolors="white", zorder=3,
)
ax.set_title(f"{n_echoes} Echoes (n\u2009=\u2009{len(subset)})", fontsize=12)
ax.set_xticks(positions)
ax.set_xticklabels([f"TE{i + 1}" for i in range(n_echoes)])
ax.set_xlabel("Echo Number")
ax.tick_params(axis="both", labelsize=10)
axes[0].set_ylabel("Echo Time (ms)")
fig.tight_layout()
plt.show()
# The TR column header carries its unit and has been renamed before
# ("TR" -> "TR (s)"), so match it by prefix instead of hard-coding the name.
# Fail with a clear message if the header drifts to zero or several matches,
# rather than raising an opaque StopIteration mid-build.
tr_matches = [c for c in metable.columns if c.strip().startswith("TR")]
if len(tr_matches) != 1:
raise ValueError(
f"Expected exactly one 'TR' column in the study-parameters sheet, "
f"found {tr_matches!r}; update the column selection in this cell."
)
tr_col = tr_matches[0]
# Columns can come back as object dtype when the source spreadsheet has blank
# or non-numeric cells; coerce to float and drop NaNs before plotting.
tr = pd.to_numeric(metable[tr_col], errors="coerce").dropna().to_numpy()
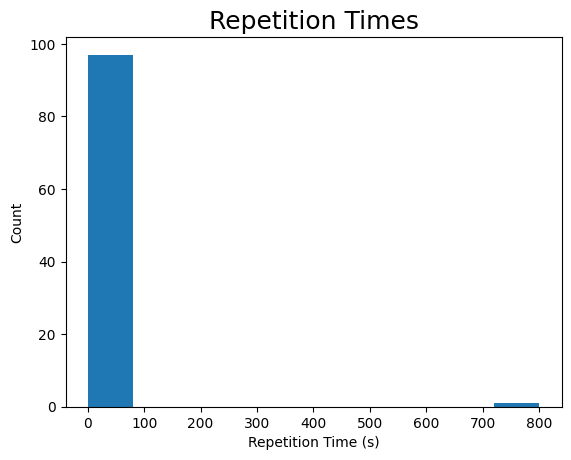
plt.hist(tr)
plt.title("Repetition Times", fontsize=18)
plt.xlabel("Repetition Time (s)")
plt.ylabel("Count")
plt.show()
x_vox = pd.to_numeric(metable.x, errors="coerce").to_numpy(dtype=float)
y_vox = pd.to_numeric(metable.y, errors="coerce").to_numpy(dtype=float)
z_vox = pd.to_numeric(metable.z, errors="coerce").to_numpy(dtype=float)
mean_vox = np.nanmean([x_vox, y_vox, z_vox], 0)
mean_vox = mean_vox[~np.isnan(mean_vox)]
plt.hist(mean_vox)
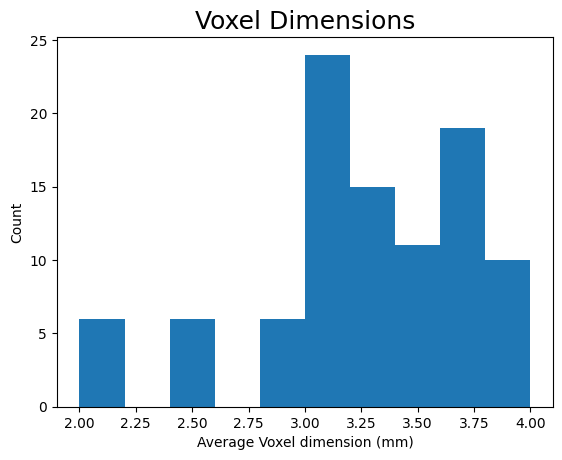
plt.title("Voxel Dimensions", fontsize=18)
plt.xlabel("Average Voxel dimension (mm)")
plt.ylabel("Count")
plt.show()
/var/folders/6z/7w14fjc11bs572r6b50rqqf40000gn/T/ipykernel_12024/26457412.py:80: RuntimeWarning: Mean of empty slice
mean_vox = np.nanmean([x_vox, y_vox, z_vox], 0)